Windows console applications. File managers
The concept and requirements to file manager had formed itself back in the DOS epoch. With the spread of operating systems with graphical user interface, other applications facilitating files handling emerged. But for many tasks and for many users orthodox file managers remain the most convenient option.
There are file managers with graphical user interface here for a long time already, however console file managers still hold on not only their proper niche, but as well a part of the space belonging in theory to file managers with a GUI. Nowadays file managers can, all in all, the same and in general the same way, but text-based file managers are more responsive to user actions. Also, even if it is not topical enough now, console file managers require less system resources, than GUI file managers of comparable functionality.
FAR Manager
Console file manager for Windows.
Among the built-in functions: FTP, Windows network, extensible archive files support, print manager, text editor. Other plugins are available: SFTP/SCP, image viewer, hex editor, syntax highlighting and auto-completion for text editor, some others.
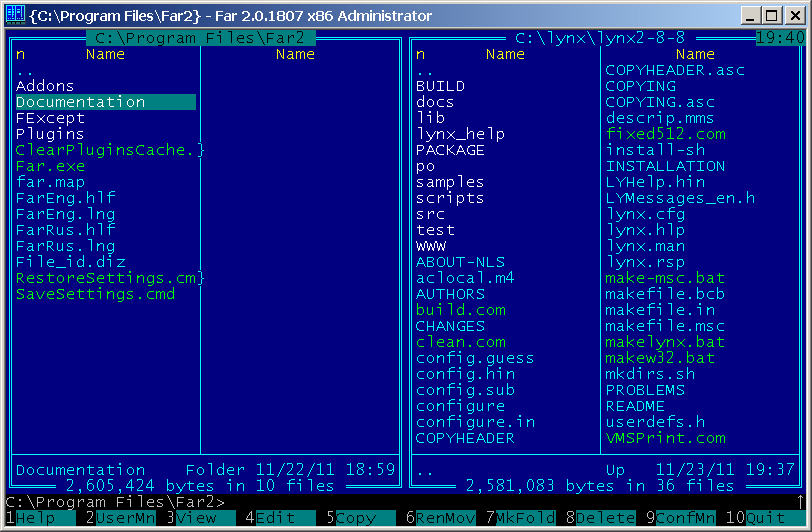
FAR Manager 2.0 - Console file manager
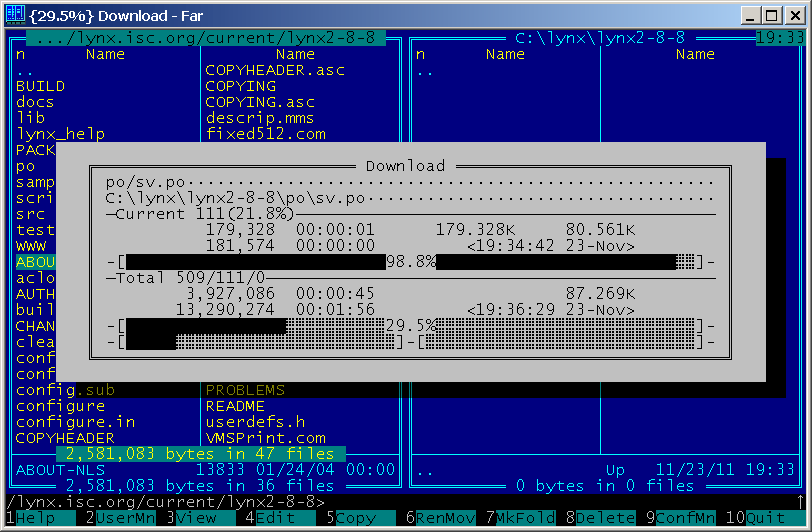
FAR Manager 2.0 - FTP, downloading files
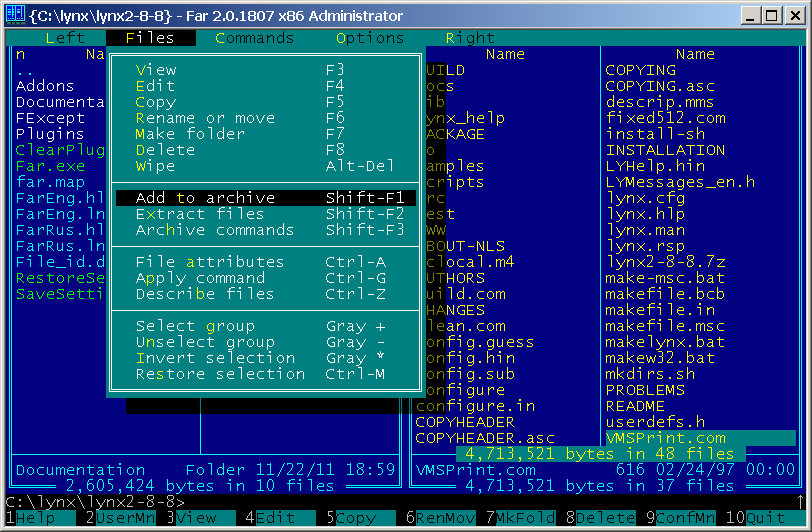
FAR Manager 2.0 - A submenu
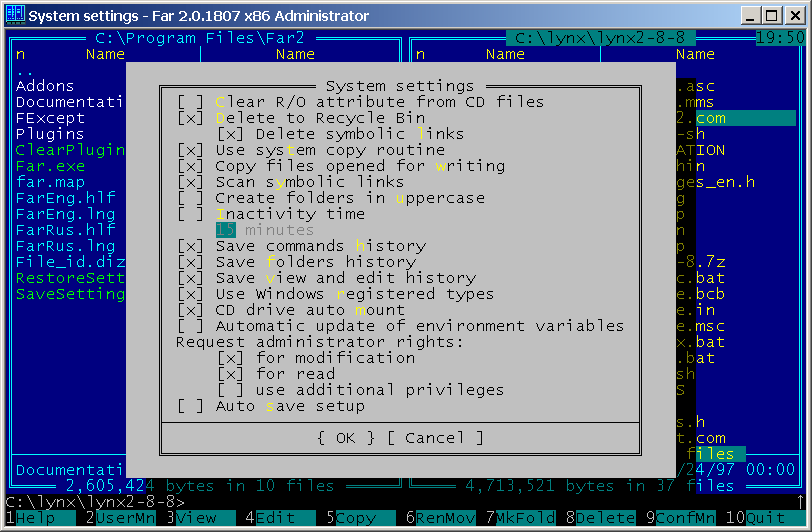
FAR Manager 2.0 - System settings
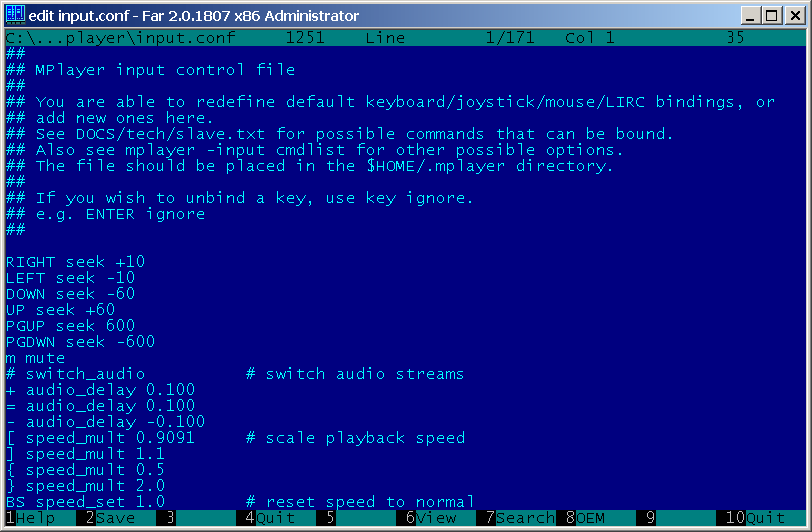
FAR Manager 2.0 - Text editor
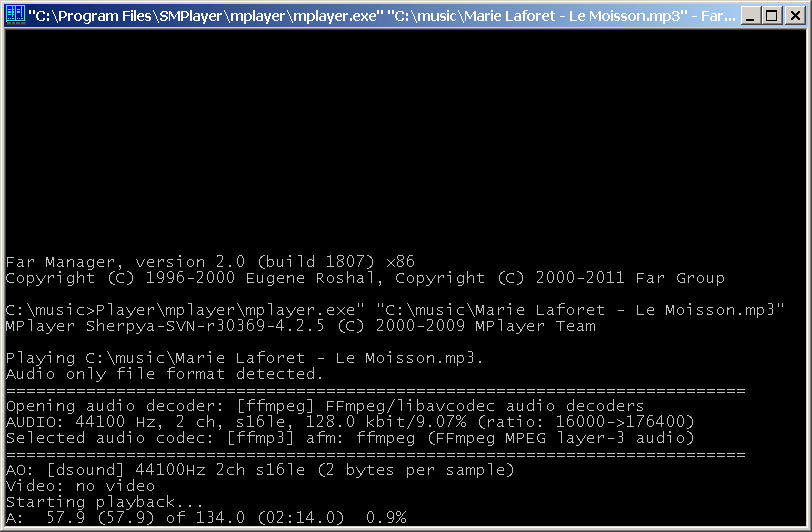
FAR Manager 2.0 - MPlayer, playing .mp3
DOS Navigator
Console file manager for Windows. A variation of the DOS file manager. There is also a version for OS/2.
Archive files support, text editor with syntax highlighting, disk editor, spreadsheet, calculator, calendar, etc. Built-in FTP client is a feature of another program based on DOS Navigator code - Necromancer's Dos Navigator (NDN).
- Home page ( open source project )
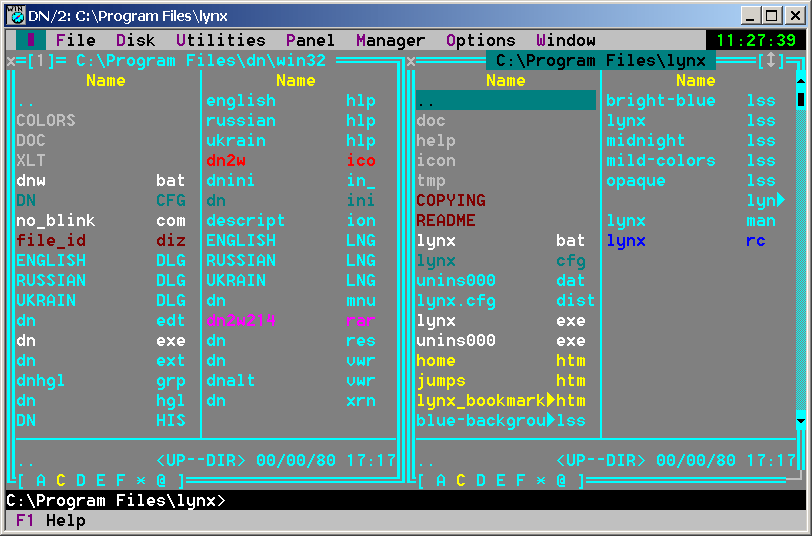
DOS Navigator 2.14 - Console file manager

DOS Navigator 2.14 - Before copying a file
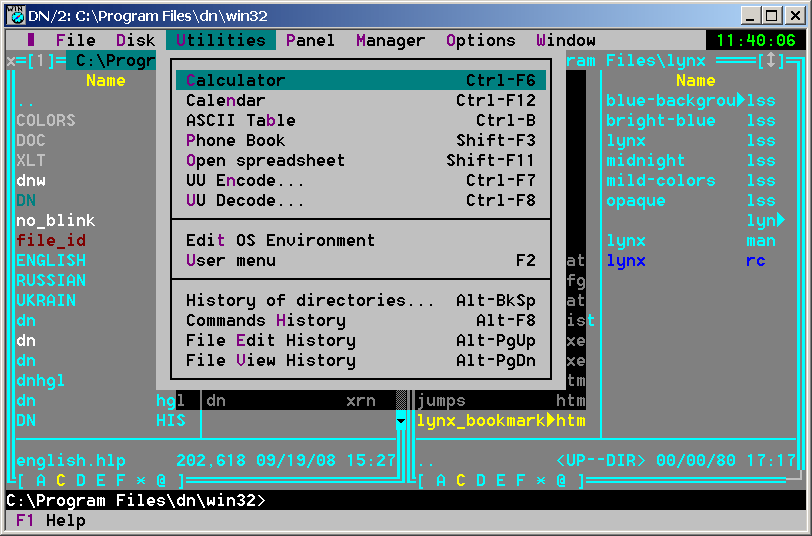
DOS Navigator 2.14 - A submenu
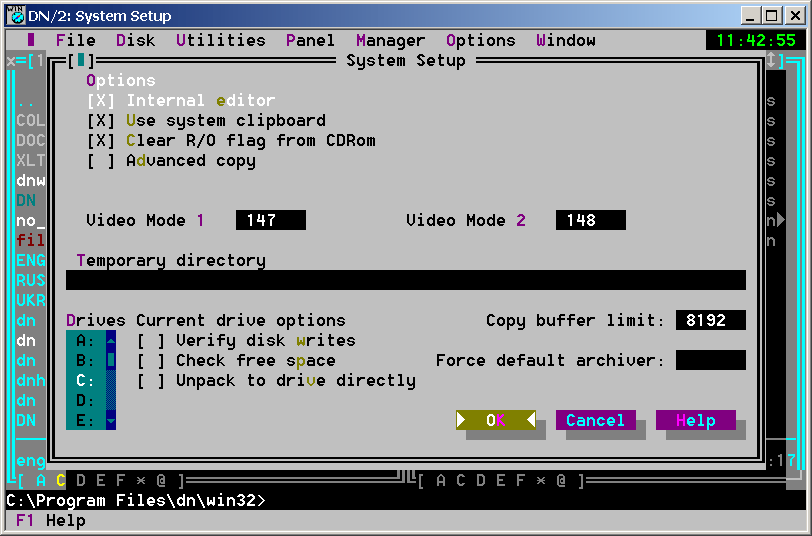
DOS Navigator 2.14 - System settings
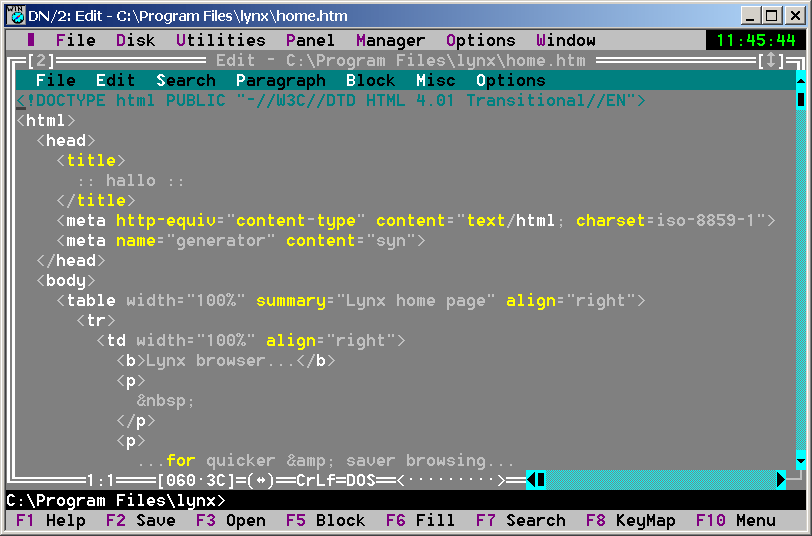
DOS Navigator 2.14 - Text editor
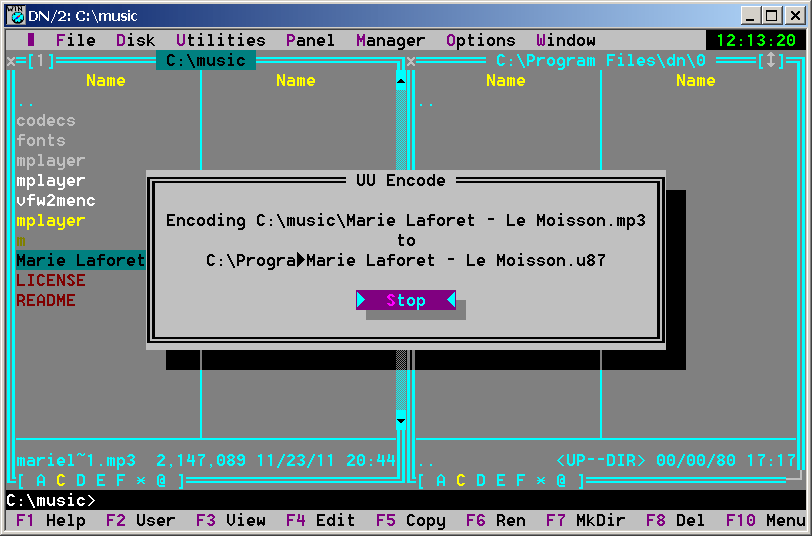
DOS Navigator 2.14 - Uuencoding a .mp3 file
File Commander
Console file manager for Windows. There are versions for OS/2, Linux, FreeBSD, OpenSolaris and other *nix systems.
Archive files support, text-editor.
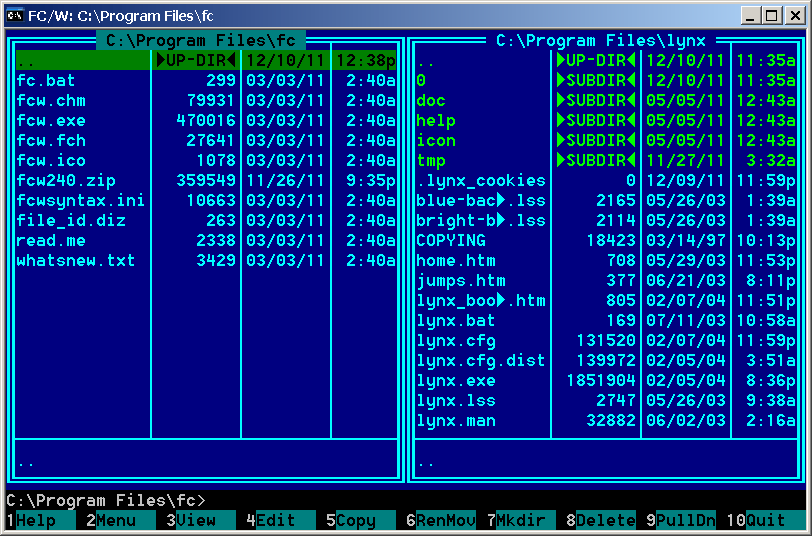
File Commander 2.40 - Console file manager
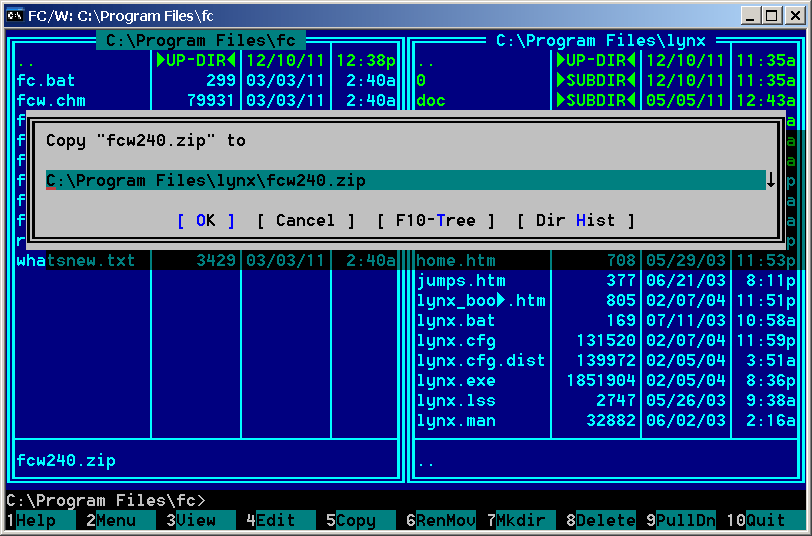
File Commander 2.40 - Before copying a file
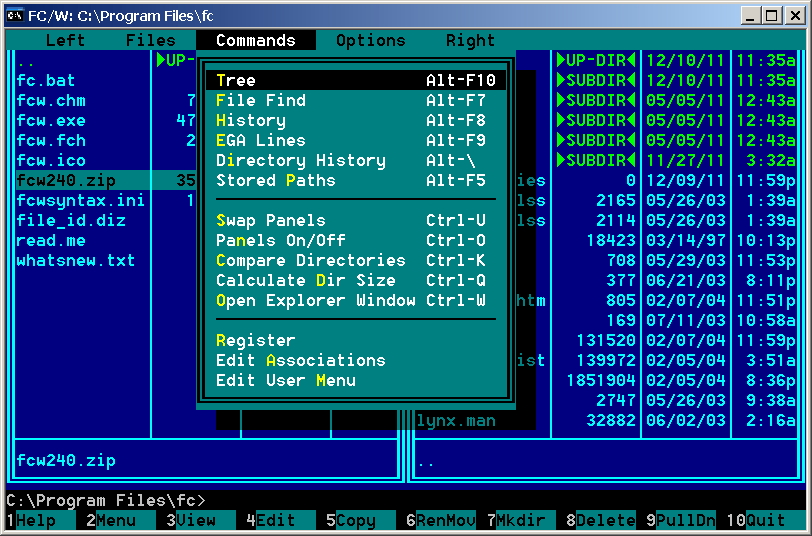
File Commander 2.40 - A submenu
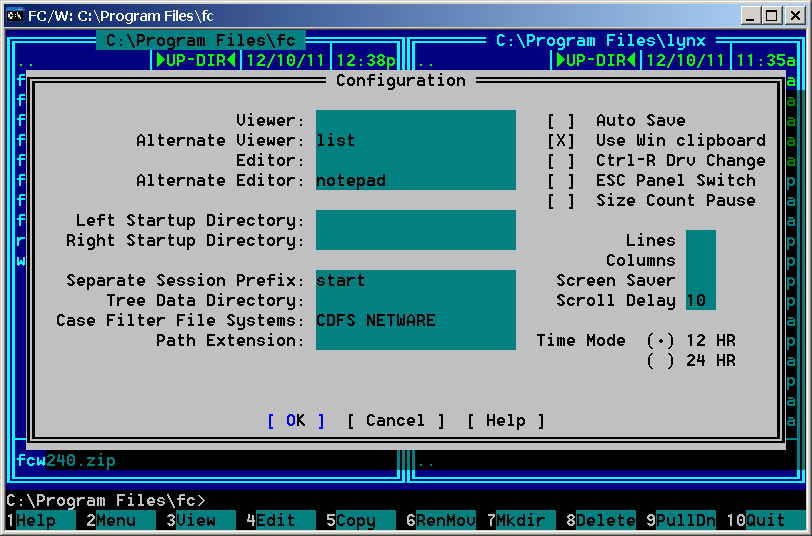
File Commander 2.40 - System settings
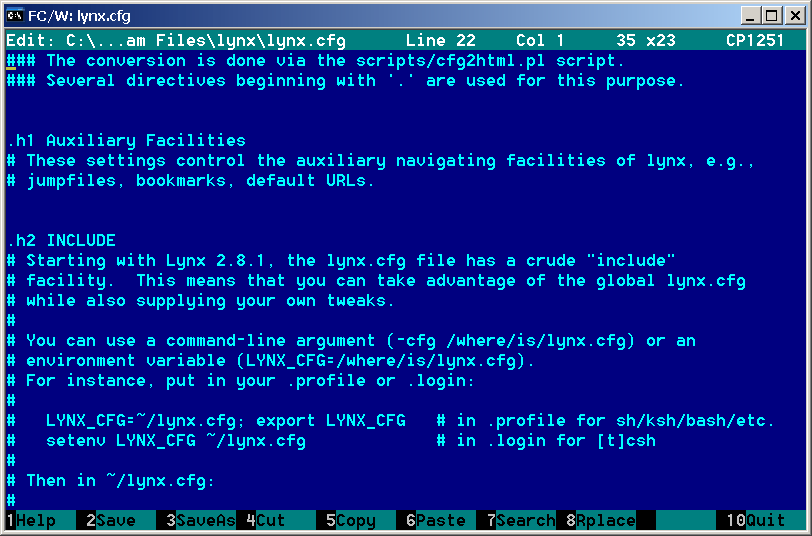
File Commander 2.40 - Text editor
File Commander 2.40 - A file info
Besides FAR Manager, DOS Navigator and File Commander console file managers with orthodox interface, there is also a quite different ZTreeWin. And DOS file managers may be used under Windows as well - with all their limitations in functionality, having their roots in DOS nature.
Operating systems
- Windows